dataset
作用
在PyTorch中,Dataset 类是torch.utils.data模块的一部分,它是一个抽象的基类,用于定义了数据集加载和处理的标准接口。通过继承这个类并实现其方法,可以创建自定义的数据集来适应各种机器学习任务。
提供的函数接口
__getitem__ 方法
这是一个抽象方法,子类必须实现它。这个方法应该根据给定的索引返回对应的数据样本。如果子类没有实现这个方法,尝试获取数据样本时会抛出 NotImplementedError。
__getitems__ 方法
这个方法被注释掉了,但它是可选的,用于加速批量样本的加载。如果实现,它应该接受一个样本索引列表,并返回一个样本列表。
__add__ 方法
这个方法允许将两个 Dataset 对象相加,返回一个新的 ConcatDataset 对象,该对象将两个数据集合并为一个连续的数据集。
__len__ 方法
返回构建的数据集的长度信息。如果子类没有实现 __len__ 方法,那么在尝试获取数据集大小时会抛出 TypeError,这是一种强制子类提供实现的方式。
特别规定:
Dataset 类定义了以下两个核心方法,任何自定义数据集都需要实现这些方法:
__len__(self):返回数据集中的样本总数。__getitem__(self, idx):根据给定的索引idx返回一个样本。这个样本可以是一个数据点,也可以是一个数据点及其对应的标签。_init_(self):初始化函数,一般要提供一个列表,列表中的元素是索引信息或者路径信息。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self,root_dir,label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir,self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
img_names = self.img_path[idx]
img_item_path = os.path.join(self.root_dir,self.label_dir,img_names)
img= Image.open(img_item_path)
label = self.label_dir
return img,label
def __len__(self):
return len(self.img_path)
root_dir = "dataset/train"
ants_label_dir = "ants_image"
bees_label_dir = "bees_image"
ants_dataset = MyData(root_dir,ants_label_dir)
bees_dataset = MyData(root_dir,bees_label_dir)
img,label = ants_dataset[0]
img.show()
print(label)
train_dataset = ants_dataset + bees_dataset
print(len(train_dataset))
|
其中__init__主要提供索引,最终提供一个列表,列表中是图片名称的索引,__getitem__主要完成由索引读取图片的过程函数,__len__用于得到列表的长度。
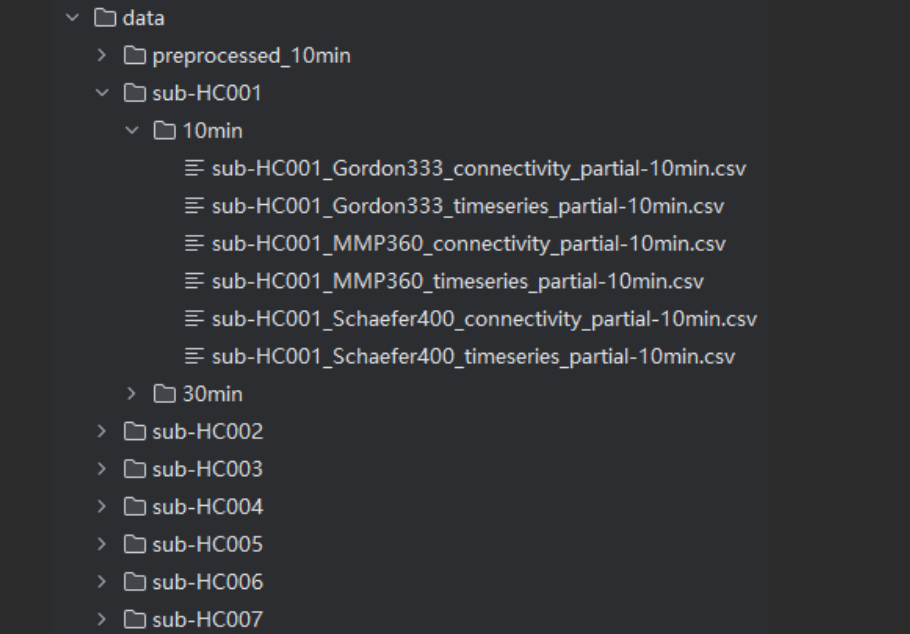
根据给定的目录信息,构建对应的dataset。要求TC和FC在dataset中一一对应。
TC: data/sub-HC001/10min/sub-HC001_Schaefer400_timeseries_partial-10min.csv
FC: data/sub-HC001/30min/sub-HC001_Schaefer400_connectivity_partial-30min.csv
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
| class Schaefer_Dataset(Dataset):
"""
配对加载10分钟TC和30分钟FC的数据集
"""
def __init__(self, data_root, subject_ids=None):
"""
初始化数据集
data_root: 数据根目录 (包含所有sub-*文件夹)
subject_ids: 可选,指定要加载的受试者ID列表
"""
self.data_root = Path(data_root)
self.subjects = self._find_subjects(subject_ids)
if not self.subjects:
raise FileNotFoundError("未找到符合条件的受试者数据")
print(f"成功初始化数据集: {len(self.subjects)} 个受试者")
def _find_subjects(self, subject_ids):
"""查找所有符合条件的受试者"""
subjects = []
for subject_dir in self.data_root.glob('sub-*'):
subject_id = subject_dir.name.replace('sub-', '')
if subject_ids and subject_id not in subject_ids:
continue
tc_file = subject_dir / "10min" / f"{subject_dir.name}_Schaefer400_timeseries_partial-10min.csv"
if not tc_file.exists():
tc_file_alt = subject_dir / "10min" / f"{subject_dir.name}_Schaefer400_timeseries.csv"
if not tc_file_alt.exists():
print(f"警告: 未找到受试者 {subject_id} 的10min TC数据")
continue
tc_file = tc_file_alt
fc_file = subject_dir / "30min" / f"{subject_dir.name}_Schaefer400_connectivity_partial-30min.csv"
if not fc_file.exists():
fc_file_alt = subject_dir / "30min" / f"{subject_dir.name}_Schaefer400_connectivity.csv"
if not fc_file_alt.exists():
print(f"警告: 未找到受试者 {subject_id} 的30min FC数据")
continue
fc_file = fc_file_alt
label = subject_id[:3] if len(subject_id) > 3 else subject_id
subjects.append({
'subject_id': subject_id,
'label': label,
'tc_path': tc_file,
'fc_path': fc_file
})
return subjects
def __len__(self):
return len(self.subjects)
def __getitem__(self, idx):
"""加载单个样本的配对数据"""
subject = self.subjects[idx]
try:
tc_data = pd.read_csv(subject['tc_path'], header=None).values.astype(np.float32)
if tc_data.shape[0] == 400:
tc_data = tc_data.T
fc_data = pd.read_csv(subject['fc_path'], header=None).values.astype(np.float32)
if fc_data.shape[0] == 400:
if fc_data.shape[1] != 400:
raise ValueError(f"FC矩阵形状不正确: {fc_data.shape}")
fc_data = 0.5 * (fc_data + fc_data.T)
else:
raise ValueError(f"FC矩阵形状不正确: {fc_data.shape}")
return {
'tc_data': torch.tensor(tc_data, dtype=torch.float32),
'fc_data': torch.tensor(fc_data, dtype=torch.float32),
'subject_id': subject['subject_id'],
'label': subject['label']
}
except Exception as e:
print(f"加载文件出错: {str(e)}")
print(f"TC文件: {subject['tc_path']}")
print(f"FC文件: {subject['fc_path']}")
raise
|
__init__函数也是提供了索引列表,只是这里提供的是列表的列表。subject的每个元素也是一个列表,包含了dataset元素中所要有的subject_id,label,tc_file和fc_file。__getitem__函数主要通过构建的列表完成加载单个样本的配对数据。
dataloader
1. 接收数据集(dataset)
DataLoader 首先关联定义的 Dataset 实例,通过数据集的两个核心方法获取基础信息:
- 调用
dataset.__len__() 知道总样本数(用于计算总批次);
- 调用
dataset.__getitem__(idx) 按索引 idx 获取单个样本(如第 0 个样本的 TC/FC 数据)。
2.确定批次参数
根据传入的参数(batch_size、shuffle 等),DataLoader 规划如何提取样本:
batch_size=4:每批包含 4 个样本;shuffle=True(训练集):每个 epoch 开始前,随机打乱所有样本的顺序,避免模型学习到样本顺序的规律;shuffle=False(验证 / 测试集):保持样本顺序不变,方便结果对齐。
3:多线程加载单个样本(可选)
如果设置了 num_workers>0(如 num_workers=2),DataLoader 会启动多个子线程并行加载单个样本,加速数据读取:
- 每个线程会调用
dataset.__getitem__(idx) 获取单个样本(如线程 1 加载 idx=0,线程 2 加载 idx=1);
- 代码中
num_workers=0(默认),表示单线程加载(适合调试,多线程可能需注意 Windows 系统兼容性)。如果复制别人的代码在dataloader报错了,很可能是你的Windows环境不适合num_workers>0的情况
4:用 collate_fn 组装批次数据
这一步需要自定义了,不同的数据集collate_fn函数可能不一样。collate_fn 是 PyTorch DataLoader 中的一个自定义批量数据组装函数,用于将多个零散的单样本数据 “拼接” 成一个统一的批次数据(batch)。由于单个样本是字典(包含 tc_data、fc_data 等),DataLoader 需要用 collate_fn 将多个样本 “拼接” 成批次数据:def collate_fn(batch):中的batch含义:当 batch_size=4 时,DataLoader 会先收集 4 个这样的样本,组成一个列表 batch = [样本1, 样本2, 样本3, 样本4]。
那为什么需要 collate_fn?
因为 每个 sample 是一个 dict,而且不同键对应的数据形状不一样,比如:
| key |
内容 |
格式 |
例子形状 |
tc_data_10min |
时间序列 |
Tensor |
(250, 400) |
fc_data_10min |
功能连接矩阵 |
Tensor |
(400, 400) |
subject_id |
被试编号 |
字符串 |
例如 '001' |
start 或 indices |
数据增强信息 |
数字 或 array |
长度可变 |
要把多个样本合并成 batch —— 不同类型就需要不同的合并方式。
例如:
✅ 对 Tensor:要 torch.stack
1
| tc_batch = torch.stack([tc1, tc2, tc3, tc4]) # → (4, 250, 400)
|
✅ 对数字:要做成一维 Tensor
1
| start_batch = torch.tensor([10, 20, 30, 40])
|
✅ 对字符串 ID:不能堆叠 → 保留成列表
1
| subject_ids = ['001', '002', '003', '004']
|
collate_fn 就是在定义:如何把这些单个样本合并成批次。
如果没有自定义 collate_fn,会怎样?
PyTorch 默认会粗暴尝试 stack
但如果 batch 中某个键不是 Tensor(比如 subject_id 是 string),就会 报错。
一句话总结
1
| collate_fn 决定了 DataLoader 如何把「单个样本」合并成「一个 batch」。
|
它的任务是:
| 类型 |
collate_fn 会做什么 |
| Tensor / ndarray |
torch.stack() 变成 (batch, …) |
| 数字 |
转为 tensor 一起合并 |
| 字符串、无法堆叠的数据 |
保留为列表,不报错 |
为什么你一定需要自定义 collate_fn?
因为你的 Dataset:
- 不同增强模式返回的字段不一样
- 样本字段包含 Tensor + 数字 + 字符串
- 如果不自定义会直接报错
自定义 collate_fn = 不改 Dataset 就能适配所有模式 ✅
5:返回批次数据并循环迭代
用 for batch in train_loader 循环时,DataLoader 会按上述步骤不断生成批次数据,直到遍历完所有样本:
- 每个
batch 是 collate_fn 返回的字典,包含批量的 tc_data、fc_data 等;
- 一个 epoch 结束后(所有样本都被加载过一次),如果
shuffle=True,会重新打乱样本顺序,开始下一个 epoch
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| def create_paired_dataloader(dataset, batch_size=4, shuffle=True, num_workers=0):
"""
创建用于配对TC和FC数据的DataLoader
参数:
dataset: Preprocess_Schaefer_Dataset实例
batch_size: 批次大小
shuffle: 是否打乱数据
num_workers: 数据加载线程数
"""
def collate_fn(batch):
"""自定义批次组装函数"""
tc_data = torch.stack([item['tc_data'] for item in batch])
fc_data = torch.stack([item['fc_data'] for item in batch])
subject_ids = [item['subject_id'] for item in batch]
labels = [item['label'] for item in batch]
return {
'tc_data': tc_data,
'fc_data': fc_data,
'subject_ids': subject_ids,
'labels': labels
}
return DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
collate_fn=collate_fn,
num_workers=num_workers,
pin_memory=True if torch.cuda.is_available() else False
)
|
划分dataset
主要使用train_test_split函数。导入方法如下
1
| from sklearn.model_selection import train_test_split
|
train_test_split(\*arrays, test_size=None, train_size=None, random_state=None, shuffle=True, stratify=None)
参数说明:
*arrays: 单个数组或元组,表示需要划分的数据集。如果传入多个数组,则必须保证每个数组的第一维大小相同。
test_size: 测试集的大小(占总数据集的比例)。默认值为0.25,即将传入数据的25%作为测试集。
train_size: 训练集的大小(占总数据集的比例)。默认值为None,此时和test_size互补,即训练集的大小为(1-test_size)。
random_state: 随机数种子。可以设置一个整数,用于复现结果。默认为None。
shuffle: 是否随机打乱数据。默认为True。
stratify: 可选参数,用于进行分层抽样。传入标签数组,保证划分后的训练集和测试集中各类别样本比例与原始数据集相同。默认为None,即普通的随机划分。
返回值说明:
该函数返回一个元组(X_train, X_test, y_train, y_test),其中X_train表示训练集的特征数据,X_test表示测试集的特征数据,y_train表示训练集的标签数据,y_test表示测试集的标签数据。
“先按规则划分 ID,再用划分好的 ID 去提取对应数据”,最终实现数据集的分类(训练集 / 验证集 / 测试集)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| from sklearn.model_selection import train_test_split
from data_set import Schaefer_Dataset
def split_dataset(dataset, test_size=0.2, val_size=0.1, random_state=42):
"""
划分训练集、验证集和测试集
确保每个标签组内按比例划分
"""
subject_ids = dataset.get_subject_ids()
labels = dataset.get_labels()
train_val_ids, test_ids, train_val_labels, _ = train_test_split(
subject_ids,
labels,
test_size=test_size,
stratify=labels,
random_state=random_state
)
train_ids, val_ids = train_test_split(
train_val_ids,
test_size=val_size / (1 - test_size),
stratify=train_val_labels,
random_state=random_state
)
train_dataset = Schaefer_Dataset(dataset.data_root, subject_ids=train_ids)
val_dataset = Schaefer_Dataset(dataset.data_root, subject_ids=val_ids)
test_dataset = Schaefer_Dataset(dataset.data_root, subject_ids=test_ids)
print(f"数据集划分结果:")
print(f" 训练集: {len(train_dataset)} 个样本")
print(f" 验证集: {len(val_dataset)} 个样本")
print(f" 测试集: {len(test_dataset)} 个样本")
return train_dataset, val_dataset, test_dataset
|

